Many of us use Git on day to day basis but I feel most of us don’t even care to look under the hood. Well, I agree with most of people on this: “If it works fine, why the hell would you touch it?”
The objective of writing this post is NOT to familiarize you all with git or version control. I intend to dig into git’s internal architecture.
Nevertheless, if you don’t know about anything about git, here are some resources to refer to:
2. Git WikiPage
3. Git Crash Course on Youtube.
Jumping on straightaway to git internals.
3 states of git in which a file can reside in:
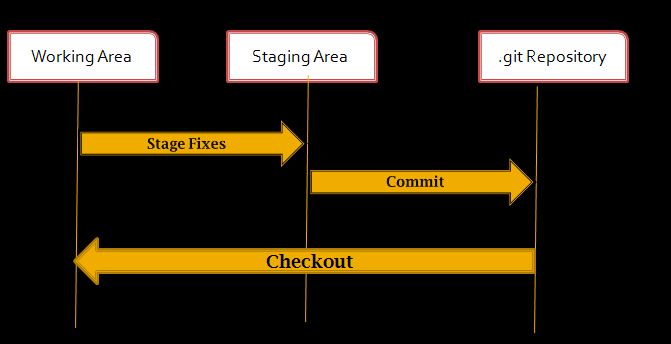
Git directory contains object database and metadata of our project.
Working area is where you modify your files related to the project.
Staging area contains those changes which should be part of next commit.
As soon as you run command “git init“ inside your working directory, a hidden folder named “.git” is created with following contents:
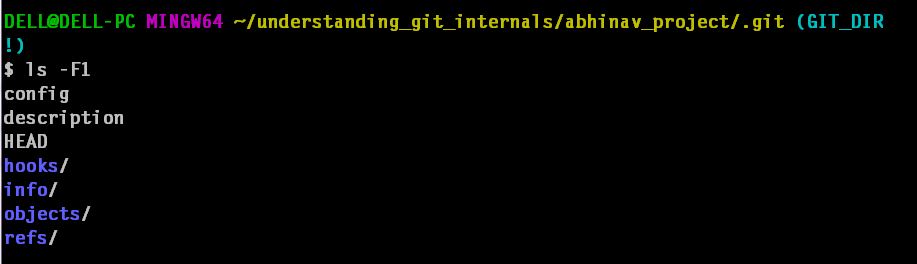
a. config – contains project-specific configuration options
b. description – used by gitweb.
c. info/ – contain information about files or pattern of files which are not to be tracked by git.
d. HEAD – will contain pointer to checked-out branch
e. hooks/ – contains a set of shell script commands which can run both on client side and server side
f. objects/ – stores all content for database
g. refs/ – stores pointers into commit objects in that data (branches, tags, remotes and more)
i. index – staging area information is stored here.
Core of Git : key-value store.
- GIT OBJECTS
Initially when we ran “git init” command, the created object/ directory had nothing. Let put something onto our project folder. I am going to put “hello world” into a file named test.txt and commit the changes.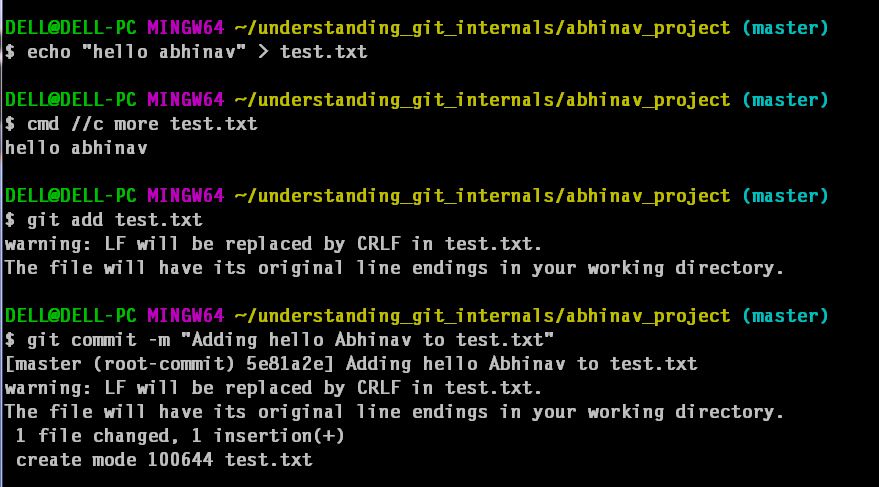 What actually happened behind the scenes:a. The content of test.txt was converted into a cryptographic hash using SHA-1 algorithm. Git creates this hash by appending strings “blob” and “<length of content>” to “<contents of the file>” and then compressing entire thing using DEFLATE algorithm. This git object type for storing files is called as blob.
What actually happened behind the scenes:a. The content of test.txt was converted into a cryptographic hash using SHA-1 algorithm. Git creates this hash by appending strings “blob” and “<length of content>” to “<contents of the file>” and then compressing entire thing using DEFLATE algorithm. This git object type for storing files is called as blob. b. This compressed thing is then stored in the object database.
b. This compressed thing is then stored in the object database.  The contents of hash can be used to access original contains for using “git cat-file” command.
The contents of hash can be used to access original contains for using “git cat-file” command.
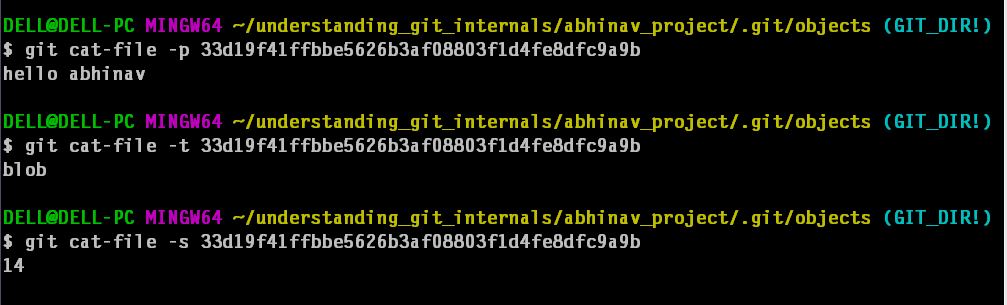
But it’s hard to remember SHA-1 key for every file as number of files increase. Also we need to store name of file and we may need to group files together. To solve this, we have something called as tree object. All the contents is stored as tree and blob objects.
A tree object can point(SHA-1 pointer) to another blob or another tree with its associated mode, type, and filename.For example, tree structure for your project can look like this:
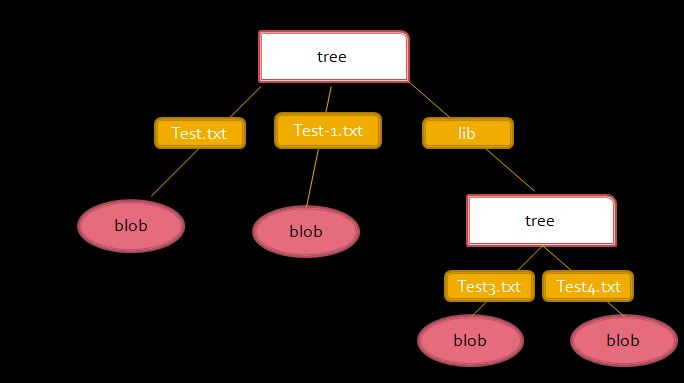
You yourself can create a simple tree object by running following commands:
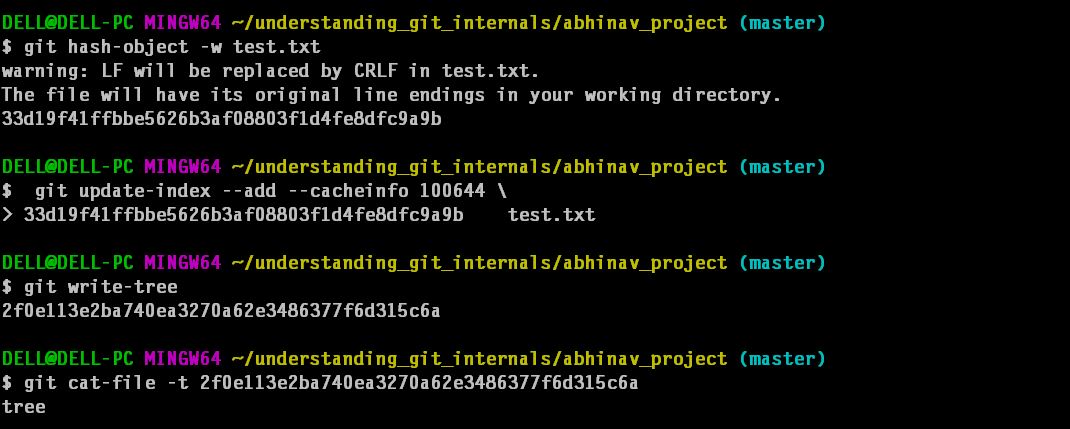
First we add some file to staging area by updating index.(This is essentially git add command) and then we run git write-tree command. The tree object(s) (is)are created from existing contents of staging area.
Now, still we still have to store somewhere information regarding why commit was created, who created the commit etc. Enter Commit-Object: another type of object which will store this information.
To create commit-object we call following commands:
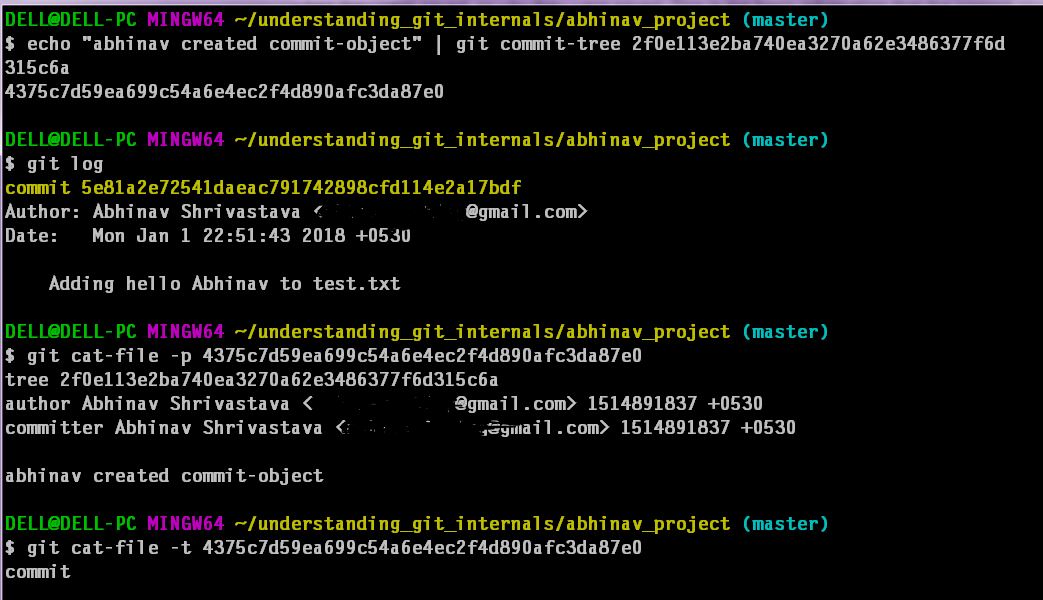
The format for a commit object : it specifies the top-level tree for the snapshot of the project at that point; the author/committer information, a blank line, and then the commit message.
Visually, the relationship between a commit object and tree object can be seen as object graph:
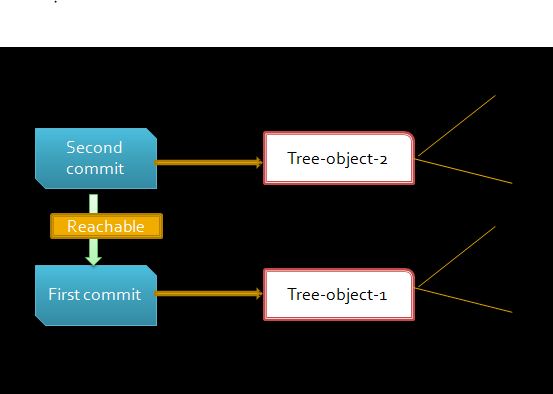
Summary of operations run during “git add” and “git commit” commands:
a. Stores blobs for changed files
b. Update the index(staging area)
c. Write out trees
d. Write commit objects that reference the top-level trees and the commits that came immediately before them.
I hope I was able to make clear at-least a few of things from git perspective. From here a lot of things can be explored such as git references, what happens when we run “git push origin master” (transfer protocols) etc,
I would like to point to an excellent resource for the same: GIT INTERNALS
That’s it for today guys, thanks for reading.